伊瓢 发自 中关村
量子位 报道 | 公众号 QbitAI
中文分词的最佳效果又被刷新了。
在今年的ACL 2020上,来自创新工场大湾区人工智能研究院的两篇论文中的模型,刷新了这一领域的成绩。
另外,在词性标注方面,TwASP模型同样刷新了成绩。
中文分词目的是在中文的字序列中插入分隔符,将其切分为词。例如,“我喜欢音乐”将被切分为“我/喜欢/音乐”(“/”表示分隔符)。
中文语言因其特殊性,在分词时面临着两个主要难点。一是歧义问题,由于中文存在大量歧义,一般的分词工具在切分句子时可能会出错。例如,“部分居民生活水平”,其正确的切分应为“部分/居民/生活/水平”,但存在“分居”、“民生”等歧义词。“他从小学电脑技术”,正确的分词是:他/从小/学/电脑技术,但也存在“小学”这种歧义词。
二是未登录词问题。未登录词指的是不在词表,或者是模型在训练的过程中没有遇见过的词。例如经济、医疗、科技等科学领域的专业术语或者社交媒体上的新词,或者是人名。这类问题在跨领域分词任务中尤其明显。
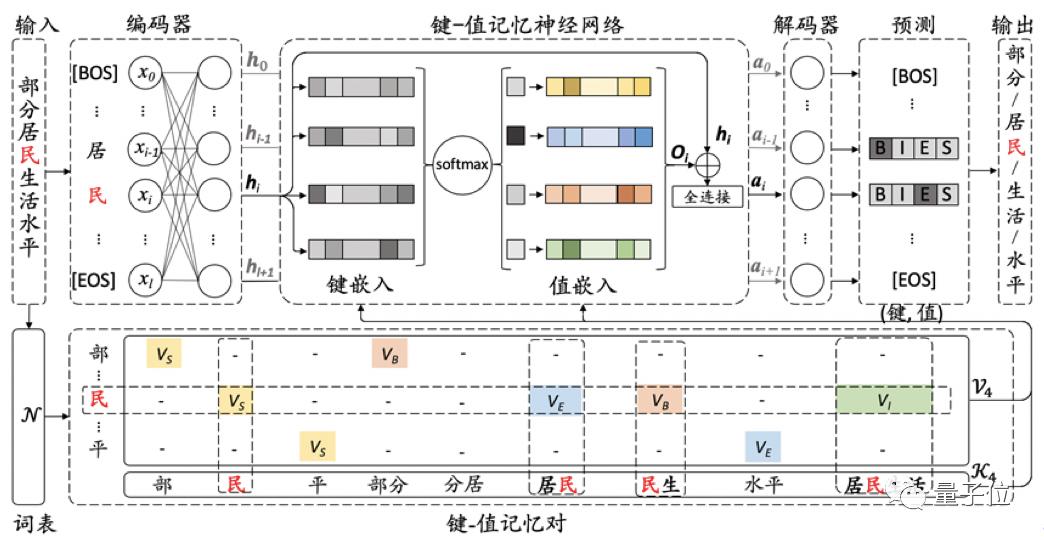
对此,《Improving Chinese Word Segmentation with Wordhood Memory Networks》这篇论文提出了基于键-值记忆神经网络的中文分词模型。
该模型利用n元组(即一个由连续n个字组成的序列,比如“居民”是一个2元组,“生活水平”是一个4元组)提供的每个字的构词能力,通过加(降)权重实现特定语境下的歧义消解。并通过非监督方法构建词表,实现对特定领域的未标注文本的利用,进而提升对未登录词的识别。
例如,在“部分居民生活水平”这句话中,到底有多少可能成为词的组块?单字可成词,如“民”;每两个字的组合可能成词,如“居民”;甚至四个字的组合也可能成词,例如“居民生活”。
“民” → 单字词
“居民” → 词尾
“民生”→ 词首
“居民生活” → 词中
把这些可能成词的组合全部找到以后,加入到该分词模型中。通过神经网络,学习哪些词对于最后完整表达句意的帮助更大,进而分配不同的权重。像“部分”、“居民”、“生活”、“水平”这些词都会被突出出来,但“分居”、“民生”这些词就会被降权处理,从而预测出正确的结果。
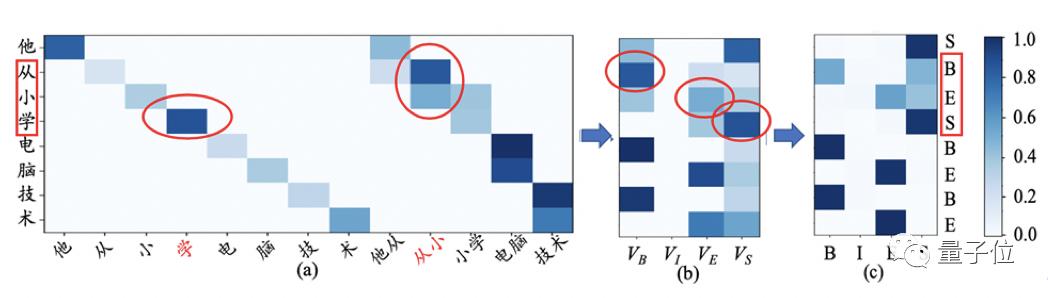
在“他从小学电脑技术” 这句话中,对于有歧义的部分“从小学”(有“从/小学”和“从小/学”两种分法),该模型能够对“从小”和“学”分配更高的权重,而对错误的n元组——“小学”分配较低的权重。
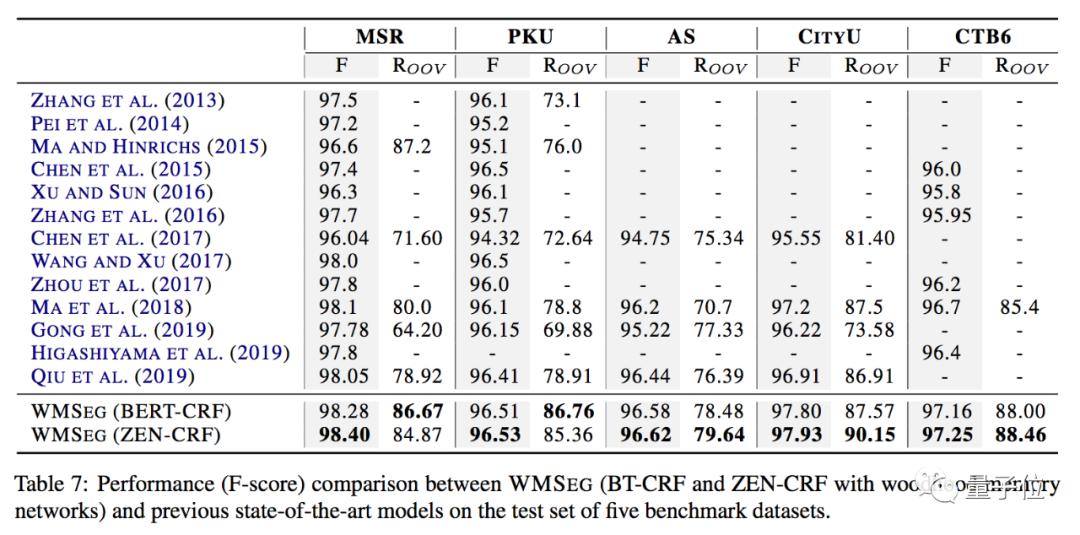
实验结果显示,该模型在5个数据集(MSR、PKU、AS、CityU、CTB6)上的表现,均达了最好的成绩。
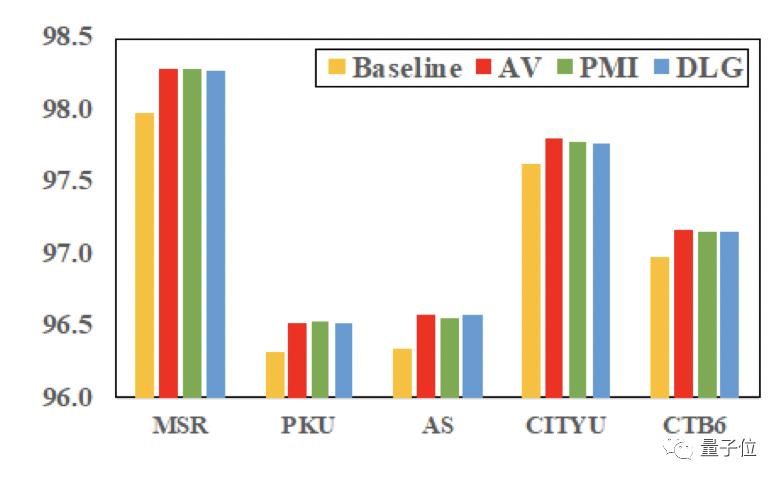
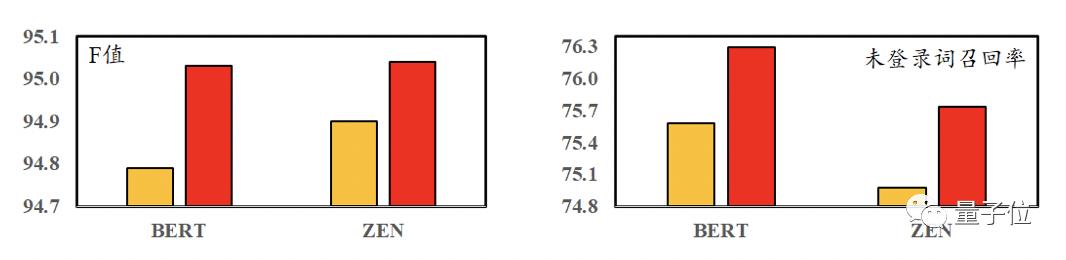
在跨领域实验中,论文使用网络博客数据集(CTB7)测试。实验结果显示,在整体F值以及未登陆词的召回率上都有比较大提升。
解决“噪音”问题
《Joint Chinese Word Segmentation and Part-of-speech Tagging via Two-way Attentions of Auto-analyzed Knowledge》论文提供了一种基于双通道注意力机制的分词及词性标注模型。
中文分词和词性标注是两个不同的任务。词性标注是在已经切分好的文本中,给每一个词标注其所属的词类,例如动词、名词、代词、形容词。词性标注对后续的句子理解有重要的作用。
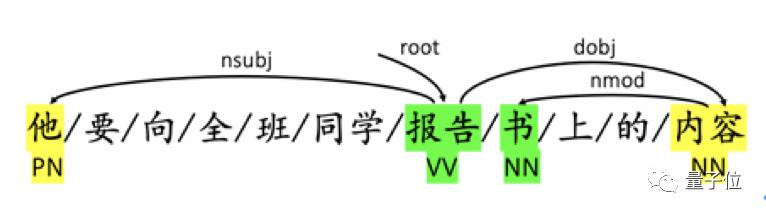
在词性标注中,歧义仍然是个老大难的问题。例如,对于“他要向全班同学报告书上的内容”中,“报告书”的正确的切分和标注应为“报告_VV/书_N”。但由于“报告书”本身也是一个常见词,一般的工具可能会将其标注为“报告书_NN”。
句法标注本身需要大量的时间和人力成本。在以往的标注工作中,使用外部自动工具获取句法知识是主流方法。在这种情况下,如果模型不能识别并正确处理带有杂音的句法知识,很可能会被不准确的句法知识误导,做出错误的预测。
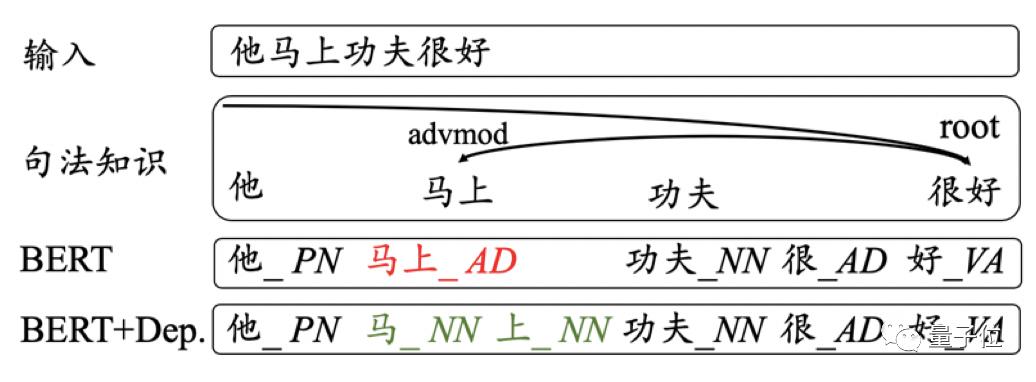
例如,在句子“他马上功夫很好”中,“马”和“上”应该分开(正确的标注应为“马_NN/上_NN”)。但按照一般的句法知识,却可能得到不准确的切分及句法关系,如“马上”。

这样一来,那些不准确的,对模型预测贡献小的上下文特征和句法知识就能被识别出来,并被分配小的权重,从而避免模型被这些有噪音的信息误导。
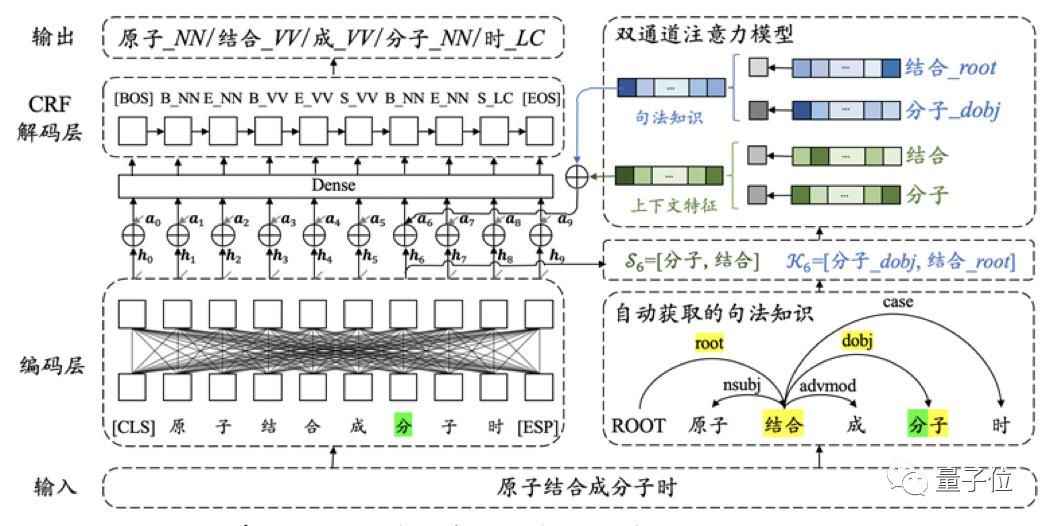
即便在自动获取的句法知识不准确的时候,该模型仍能有效识别并利用这种知识。例如,将前文有歧义、句法知识不准确的句子(“他马上功夫很好”),输入该双通道注意力模型后,便得到了正确的分词和词性标注结果。
为了测试该模型的性能,论文在一般领域和跨领域分别进行了实验。
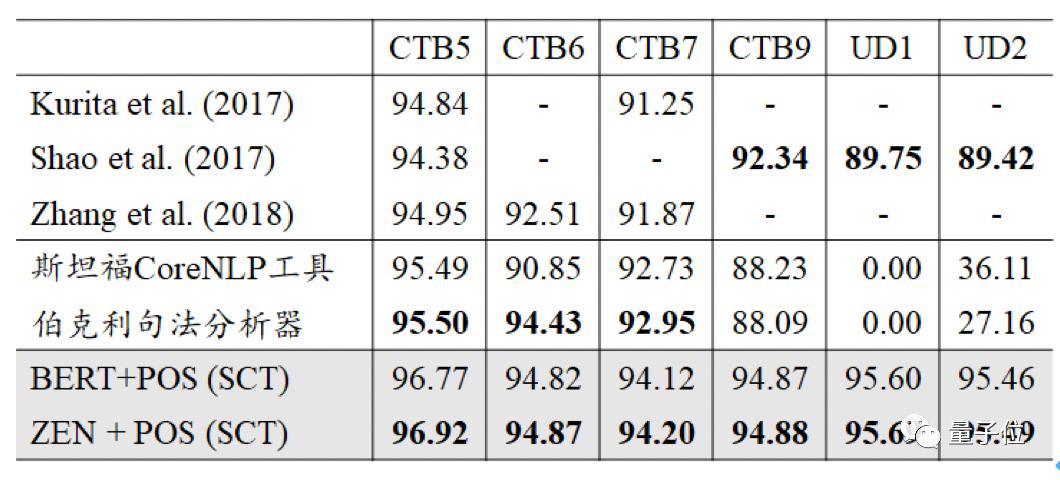
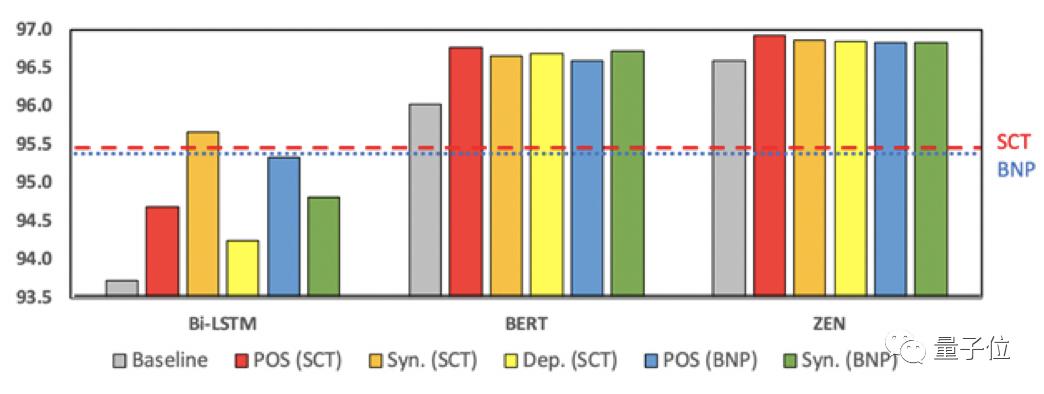
一般领域实验结果显示,该模型在5个数据集(CTB5,CTB6,CTB7,CTB9,Universal Dependencies)的表现(F值)均超过前人的工作,也大幅度超过了斯坦福大学的 CoreNLP 工具,和伯克利大学的句法分析器。
即使是在与CTB词性标注规范不同的UD数据集中,该模型依然能吸收不同标注带来的知识,并使用这种知识,得到更好的效果。
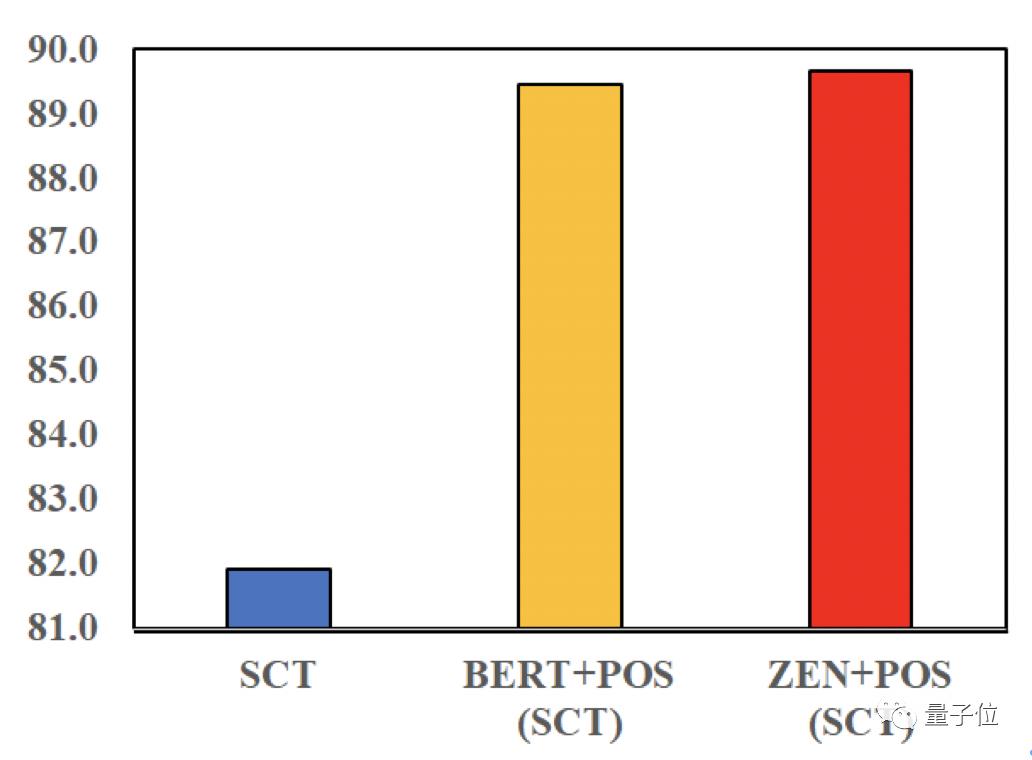
而在跨领域的实验中,和斯坦福大学的 CoreNLP 工具相比,该模型也有近10个百分点的提升。
创新工场出品
两篇论文的第一作者,是华盛顿大学博士研究生、创新工场实习生田元贺。


Improving Chinese Word Segmentation with Wordhood Memory Networks
作者:Yuanhe Tian, Yan Song, Fei Xia, Tong Zhang, Yonggang Wang
论文地址:https://www.aclweb.org/anthology/2020.acl-main.734/
GitHub:https://github.com/SVAIGBA/WMSeg
Joint Chinese Word Segmentation and Part-of-speech Tagging via Two-way Attentions of Auto-analyzed Knowledge
作者:Yuanhe Tian, Yan Song, Xiang Ao, Fei Xia, Xiaojun Quan, Tong Zhang, Yonggang Wang
论文地址:https://www.aclweb.org/anthology/2020.acl-main.735/
GitHub:https://github.com/SVAIGBA/TwASP
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。
了解AI发展现状,抓住行业发展机遇
如何关注、学习、用好人工智能?
每个工作日,量子位AI内参精选全球科技和研究最新动态,汇总新技术、新产品和新应用,梳理当日最热行业趋势和政策,搜索有价值的论文、教程、研究等。
同时,AI内参群为大家提供了交流和分享的平台,更好地满足大家获取AI资讯、学习AI技术的需求。扫码即可订阅:
AI社群 | 与优秀的人交流
