扩散模型和流匹配实际上是同一个概念的两种不同表达方式吗?
从表面上看,这两种方法似乎各有侧重:扩散模型专注于通过迭代的方式逐步去除噪声,将数据还原成清晰的样本。
而流匹配则侧重于构建可逆变换系统,目标是学习如何将简单的基础分布精确地映射到真实数据分布。
因为流匹配的公式很简单,并且生成样本的路径很直接,最近越来越受研究者们的欢迎,于是很多人都在问:
「到底是扩散模型好呢?还是流匹配好?」
现在,这个困扰已得到解答。Google DeepMind 的研究团队发现,原来扩散模型和流匹配就像一枚硬币的两面,本质上是等价的 (尤其是在流匹配采用高斯分布作为基础分布时),只是不同的模型设定会导致不同的网络输出和采样方案。
这无疑是个好消息,意味着这两种框架下的方法可以灵活搭配,发挥组合技了。比如在训练完一个流匹配模型后,不必再局限于传统的确定性采样方法,完全可以引入随机采样策略。

链接:https://diffusionflow.github.io
在这篇博客的开头,作者们写道:「我们的目标是帮助大家能够自如地交替使用这两种方法,同时在调整算法时拥有真正的自由度 —— 方法的名称并不重要,重要的是理解其本质。」
扩散模型与流匹配
扩散模型主要分为前向过程和反向两个阶段。
前向过程用公式表示为:
其中 z_t 是在时间点 t 时的带噪声数据,x 代表原始数据,ε 代表随机噪声,a_t 和 σ_t 是控制噪声添加程度的参数。
若满足
,称为「方差保持」,意味着在每个时间步骤中,噪声的方差保持不变或接近不变。
DDIM 采样器的反向过程用公式表示为:
其中,
而在流匹配中,前向过程视为数据 x 和噪声项 ε 之间的线性插值:
采样
人们普遍认为,这两个框架在生成样本的方式上有所不同:流匹配采样是确定性的,具有直线路径,而扩散模型采样是随机性的,具有曲线路径。下面文章将澄清这一误解:首先关注更简单的确定性采样,稍后再讨论随机情况。
假设你想使用训练好的降噪器模型将随机噪声转换为数据点。可以先回想一下 DDIM 的更新
,有趣的是,重新排列项可以用以下公式来表达,这里涉及几组网络输出和重新参数化:
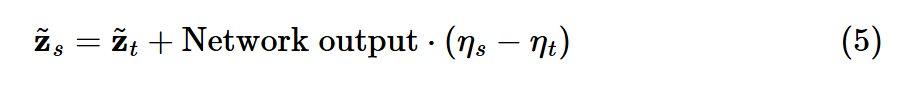
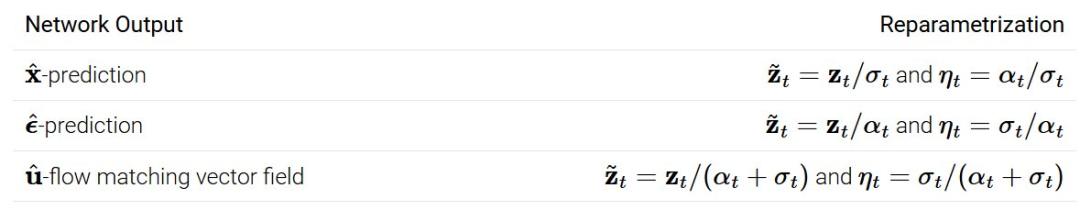
我们再回到公式(4)中的流匹配更新,和上述方程看起来很相似。如果在最后一行将网络输出设为
,并令
,可以得到
、
这样我们就恢复了流匹配更新!更准确地说,流匹配更新可以被视为重参数化采样常微分方程(ODE)的欧拉积分:

对于 DDIM 采样器而言,普遍存在以下结论:DDIM 采样器对于应用于噪声调度 α_t、σ_t 的线性缩放是不变的,因为缩放不会影响
和
,这对于其他采样器来说并不成立,例如概率流 ODE 的欧拉采样器。
为了验证上述结论,本文展示了使用几种不同的噪声调度得到的结果,每种调度都遵循流匹配调度,并具有不同的缩放因子。如下图,随意调整滑块,在最左侧,缩放因子是 1,这正是流匹配调度,而在最右侧,缩放因子是
。可以观察到 DDIM(以及流匹配采样器)总是给出相同的最终数据样本,无论调度的缩放如何。对于概率流 ODE 的欧拉采样器,缩放确实会产生真正的差异:可以看到路径和最终样本都发生了变化。

看到这里,需要思考一下。人们常说流匹配会产生直线路径,但在上图中,其采样轨迹看起来是弯曲的。
在下面的交互式图表中,我们可以通过滑块更改右侧数据分布的方差。
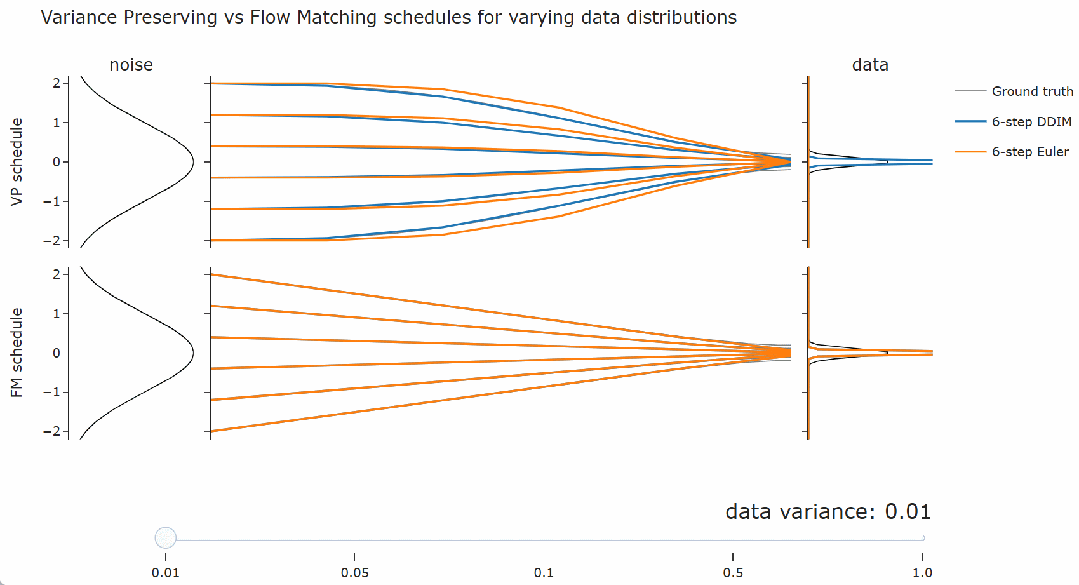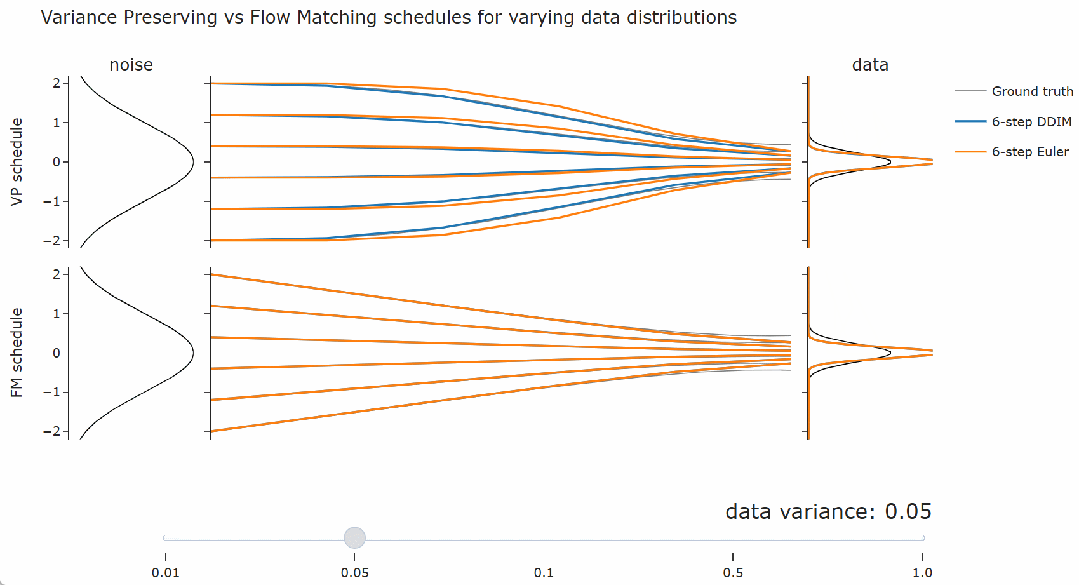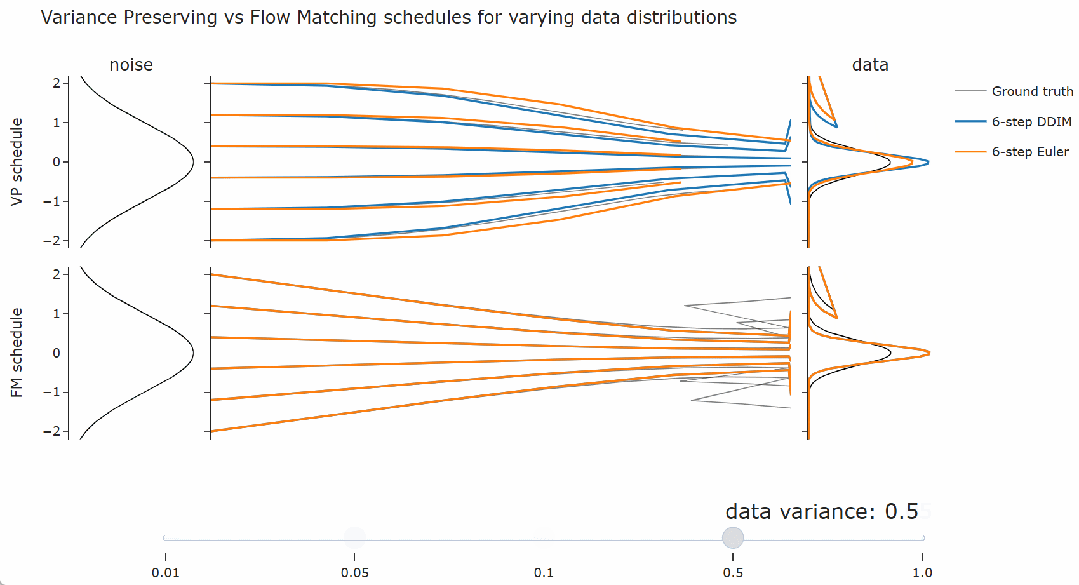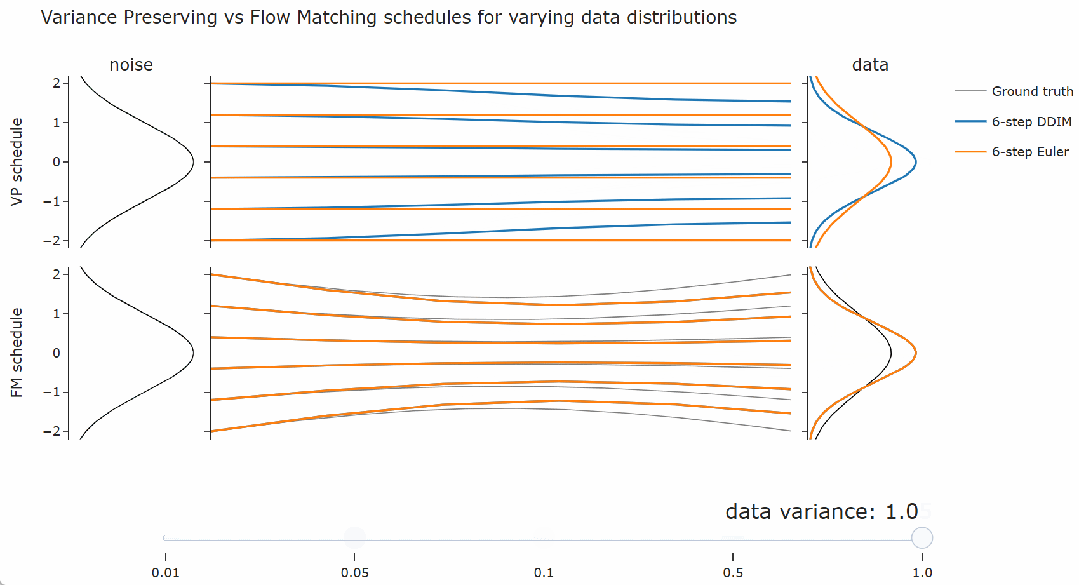
不过,在像图像这样的真实数据集上找到这样的直线路径要复杂得多。但结论仍然是相同的:最优的积分方法取决于数据分布。
我们可以从确定性采样中得到的两个重要结论:
采样器的等价性:DDIM 与流匹配采样器等价,并且对噪声调度的线性缩放不变。
对直线性的误解:流匹配调度仅在模型预测单个点时才是直线。
训练
对于扩散模型,学习模型是通过最小化加权均方误差(MSE)损失来完成的:
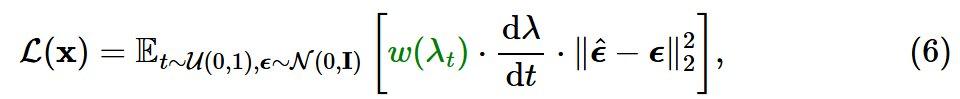
流匹配也符合上述训练目标:
网络应该输出什么
下面总结了文献中提出的几个网络输出,包括扩散模型使用的几个版本和流匹配使用的其中一个版本。

然而,在实践中,模型的输出可能会产生非常大的影响。例如,基于相似的原因,
在低噪声水平下是有问题的,因为
没有信息量,并且错误在
中被放大了。
因此,一种启发式方法是选择一个网络输出,它是
、
的组合,这适用于
和流匹配矢量场
如何选择加权函数
加权函数是损失函数中最重要的部分,它平衡了图像、视频和音频等数据中高频和低频分量的重要性。这一点至关重要,因为这些信号中的某些高频分量是人类无法感知的。如果通过加权情况来查看损失函数,可以得出以下结果:

即公式 (7) 中的条件流匹配目标与扩散模型中常用的设置相同。下面绘制了文献中常用的几个加权函数。
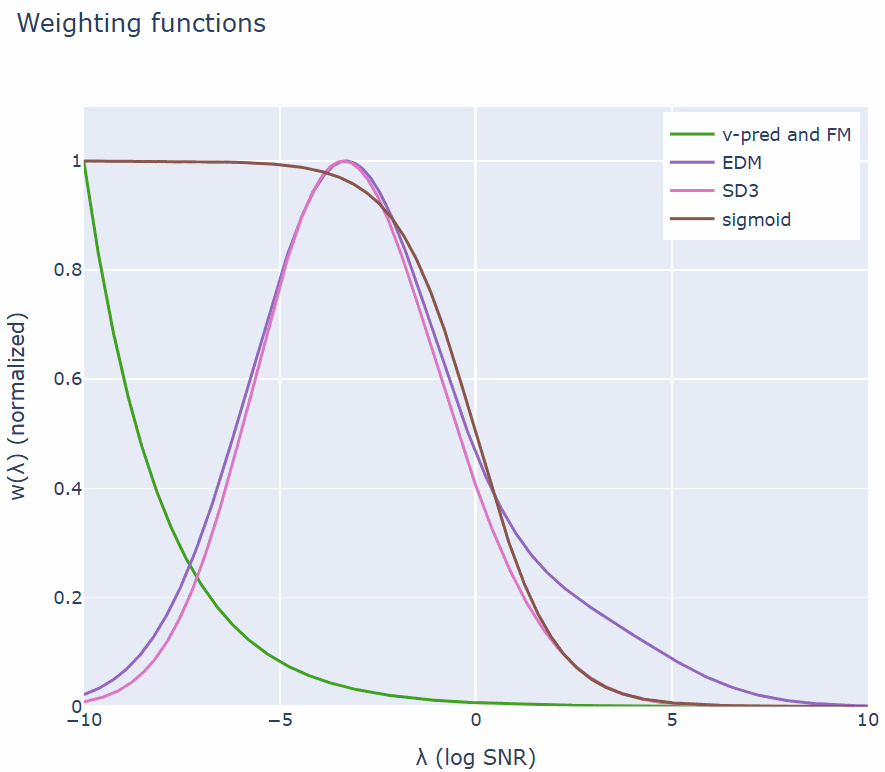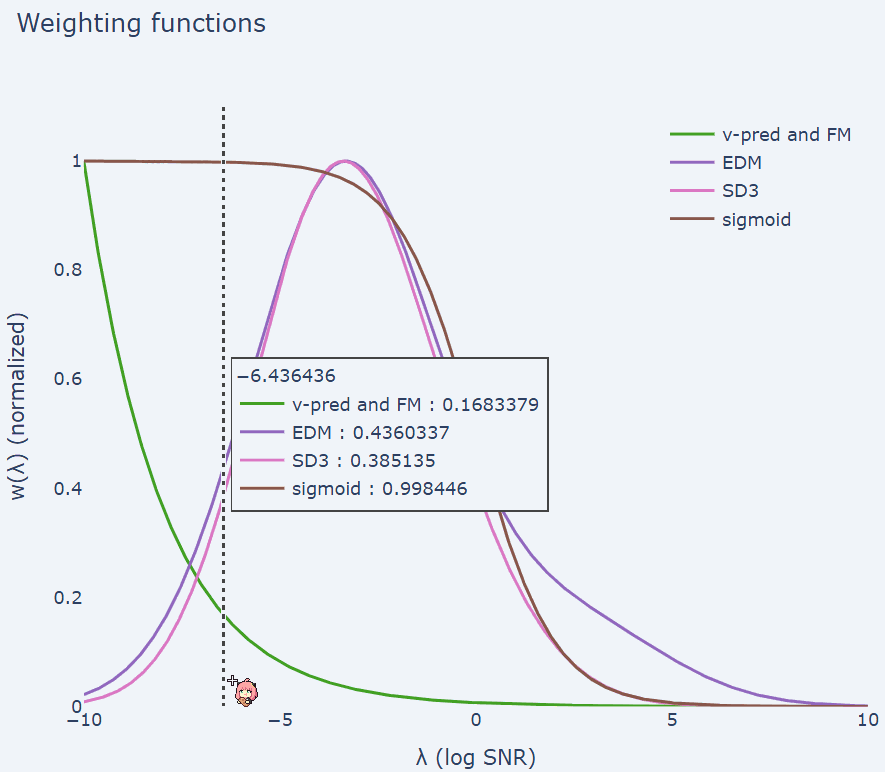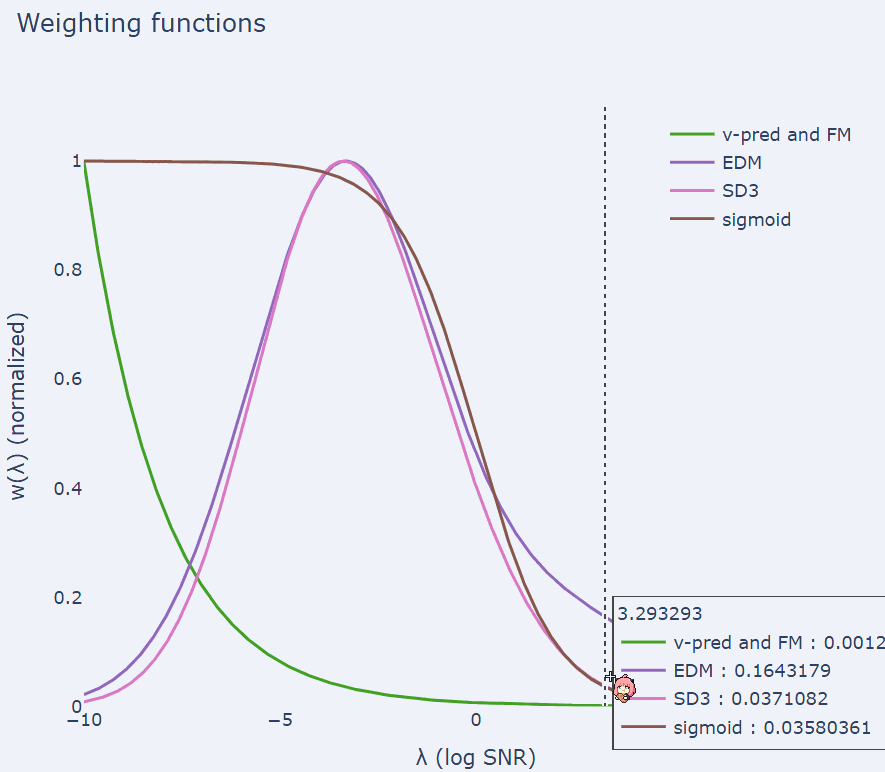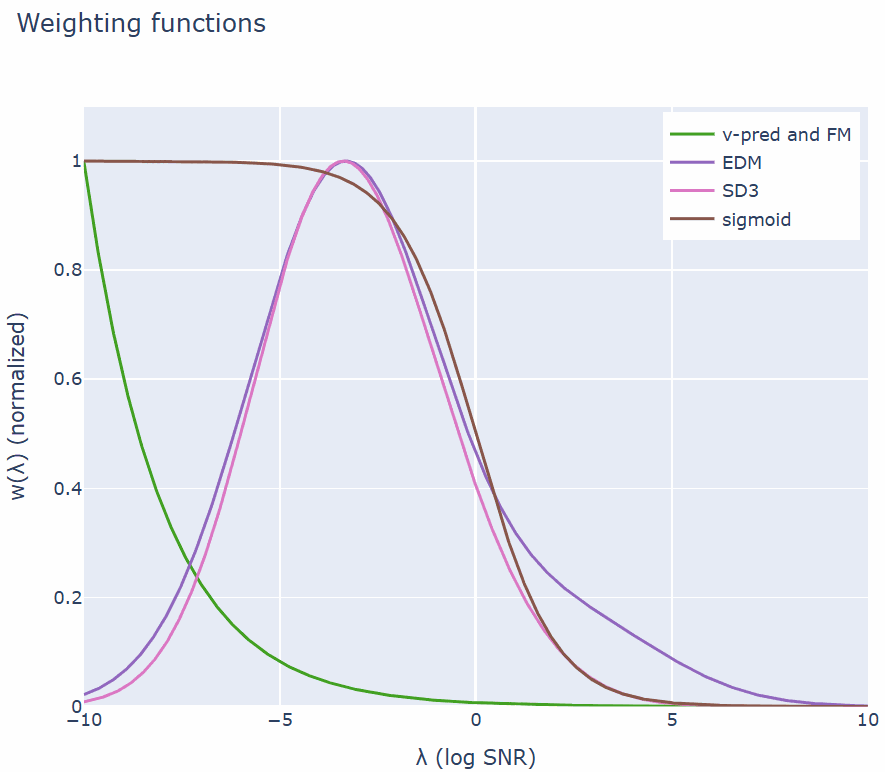
流匹配加权(也称为 v-MSE + 余弦调度加权)会随着 λ 的增加而呈指数下降。该团队在实验中发现了另一个有趣的联系:Stable Diffusion 3 加权 [9](这是流匹配的一种重新加权版本)与扩散模型中流行的 EDM 加权 [10] 非常相似。
如何选择训练噪声调度?
最后讨论训练噪声调度,因为在以下意义上,它对训练的重要程度最低:
1. 训练损失不会随训练噪声调度变化。具体来说,损失函数可以重写为
它只与端点(λ_max, λ_min)有关,但与中间的调度 λ_t 无关。在实践中,应该选择合适的 λ_max, λ_min,使得两端分别足够接近干净数据和高斯噪声。λ_t 可能仍然会影响训练损失的蒙特卡洛估计量的方差。一些文献中提出了一些启发式方法来在训练过程中自动调整噪声调度。这篇博文有一个很好的总结:https://sander.ai/2024/06/14/noise-schedules.html#adaptive
2. 类似于采样噪声调度,训练噪声调度不会随线性扩展(linear scaling)而变化,因为人们可以轻松地将线性扩展应用于 z_t,并在网络输入处进行 unscaling 以获得等价性。噪声调度的关键定义属性是对数信噪比 λ_t。
3. 人们可以根据不同的启发式方法为训练和采样选择完全不同的噪声调度:对于训练,最好有一个噪声调度来最小化蒙特卡洛估计量的方差;而对于采样,噪声调度与 ODE / SDE 采样轨迹的离散化误差和模型曲率更相关。
总结
下面给出了训练扩散模型 / 流匹配的一些要点:
加权中的等价性:加权函数对于训练很重要,它平衡了感知数据不同频率分量的重要性。流匹配加权与常用的扩散训练加权方法相同。
训练噪声调度的不重要性:噪声调度对训练目标的重要性要小得多,但会影响训练效率。
网络输出的差异:流匹配提出的网络输出是新的,它很好地平衡了
更深入地理解采样器
这一节将更详细地介绍各种不同的采样器。
回流算子
流匹配中的回流(Reflow)运算是使用直线将噪声与数据点连接起来。通过基于噪声运行一个确定性的采样器,可以得到这些 (数据,噪声) 对。然后,可以训练模型,使之可以根据给定噪声直接预测数据,而无需采样。在扩散技术的相关文献中,这同样的方法是最早的蒸馏技术之一。
确定性采样器与随机采样器
此前已经讨论了扩散模型或流匹配的确定性采样器。另一种方法是使用随机采样器,例如 DDPM 采样器。
执行一个从 λ_t 到 λ_t+Δλ 的 DDPM 采样步骤完全等价于执行一个到 λ_t+2Δλ 的 DDIM 采样步骤,然后通过执行前向扩散重新噪声化到 λ_t+Δλ。也就是说,通过前向扩散重新噪声化恰好逆转了 DDIM 所取得的一半进展。为了理解这一点,让我们看一个 2D 示例。从相同的高斯分布混合开始,我们可以执行一个小的 DDIM 采样步骤,左图带有更新反转的符号,右图则是一个小的前向扩散步骤:
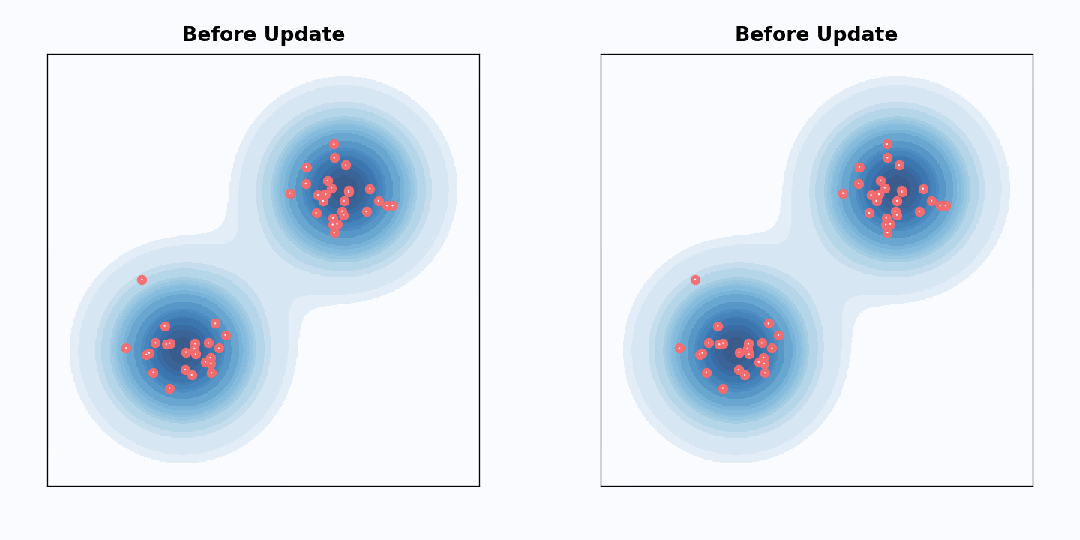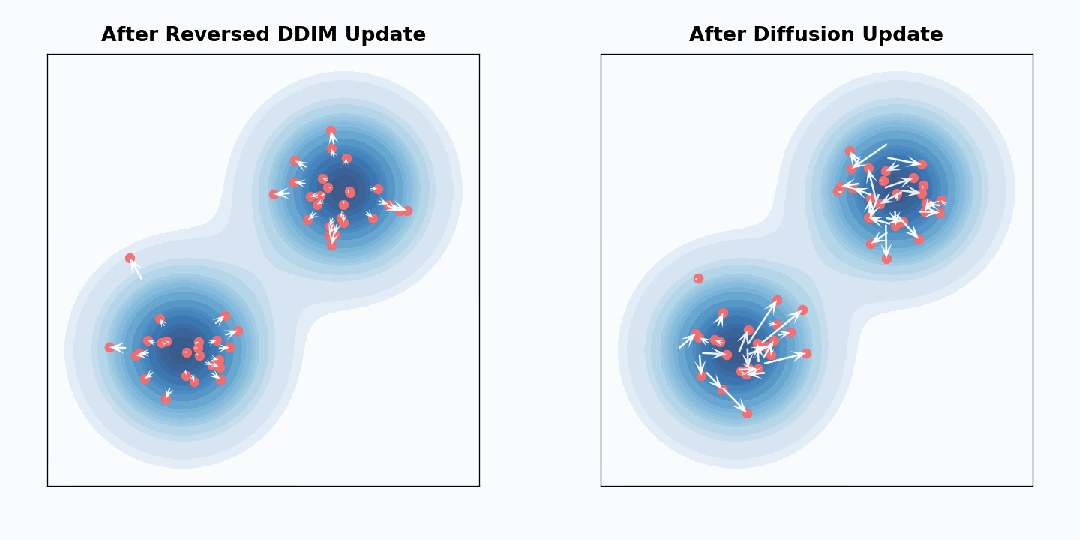
对于单个样本而言,这些更新的行为完全不同:反转的 DDIM 更新始终将每个样本推离分布模式,而扩散更新完全是随机的。但是,在汇总所有样本时,更新后得到的分布是相同的。因此,如果执行 DDIM 采样步骤(不反转符号),然后执行前向扩散步骤,则整体分布与更新之前的分布保持不变。
通过重新加噪来撤消的 DDIM 步骤的比例是一个超参数,并且可以自由选择(即不必一定是 DDIM 步骤的一半)。这个超参数在《Elucidating the design space of diffusion-based generative models》中被称为 level of churn,可译为「搅动水平」。有趣的是,将搅动添加到采样器的效果是:减少采样过程早期做出的模型预测对最终样本的影响,并增加对后续预测的权重。如下图所示:
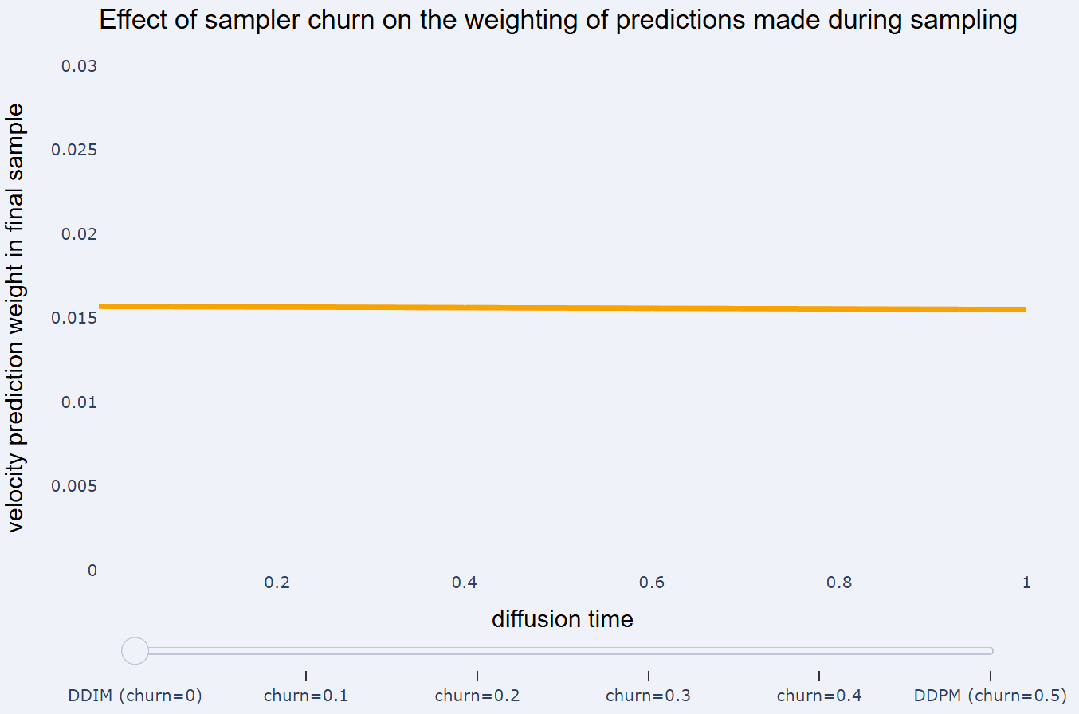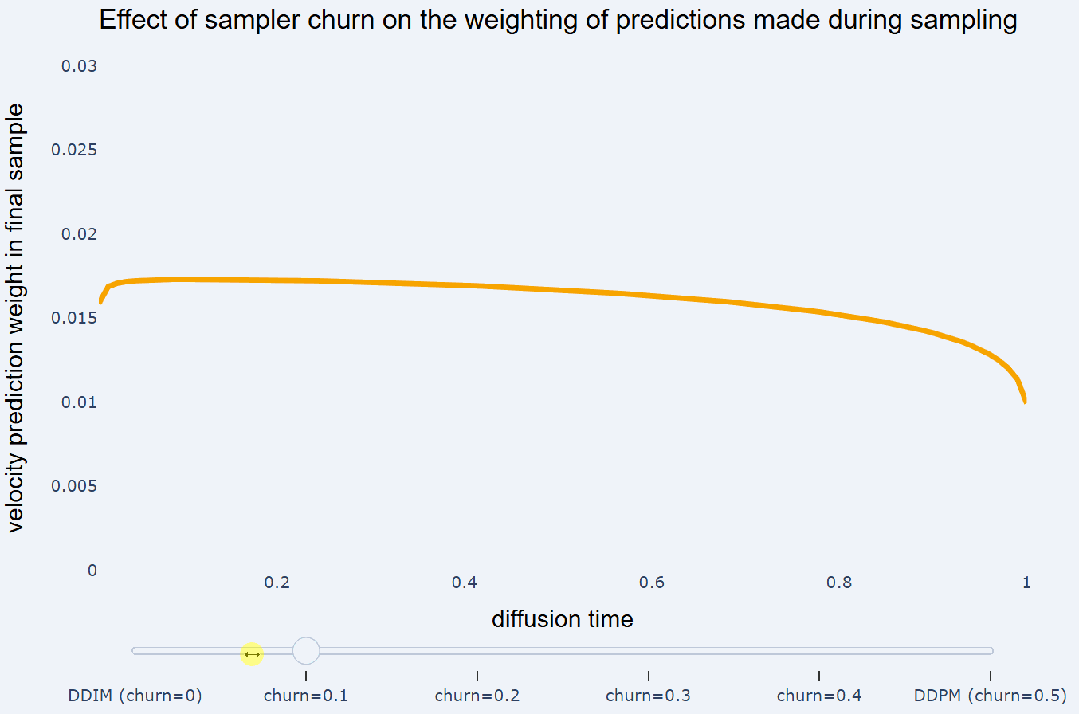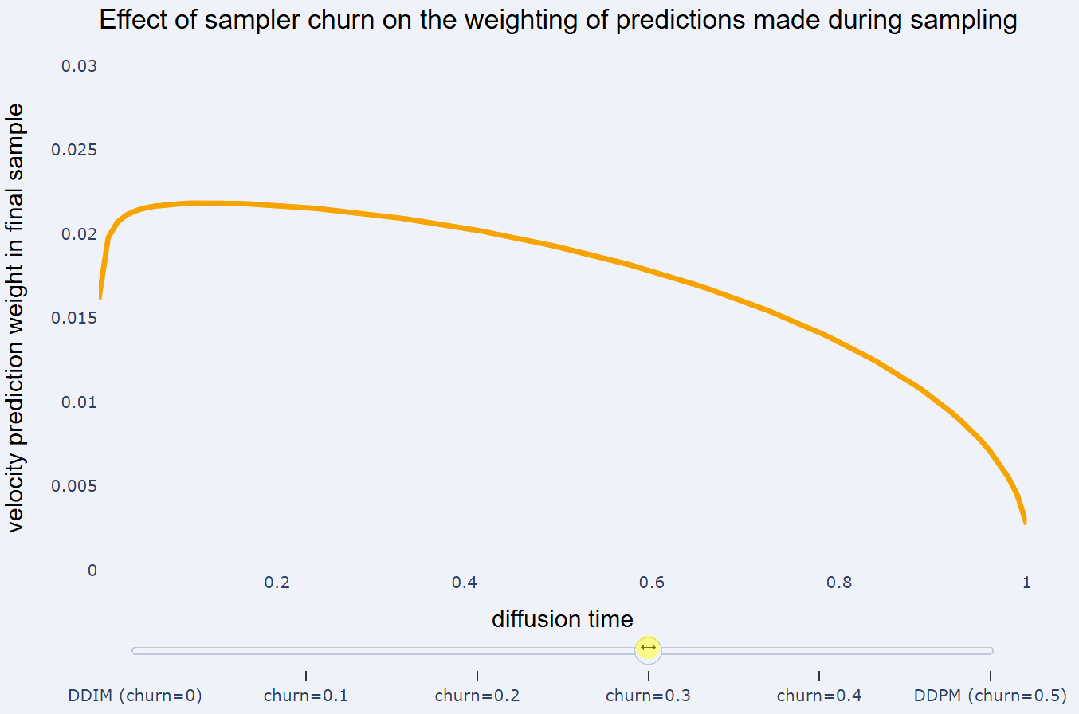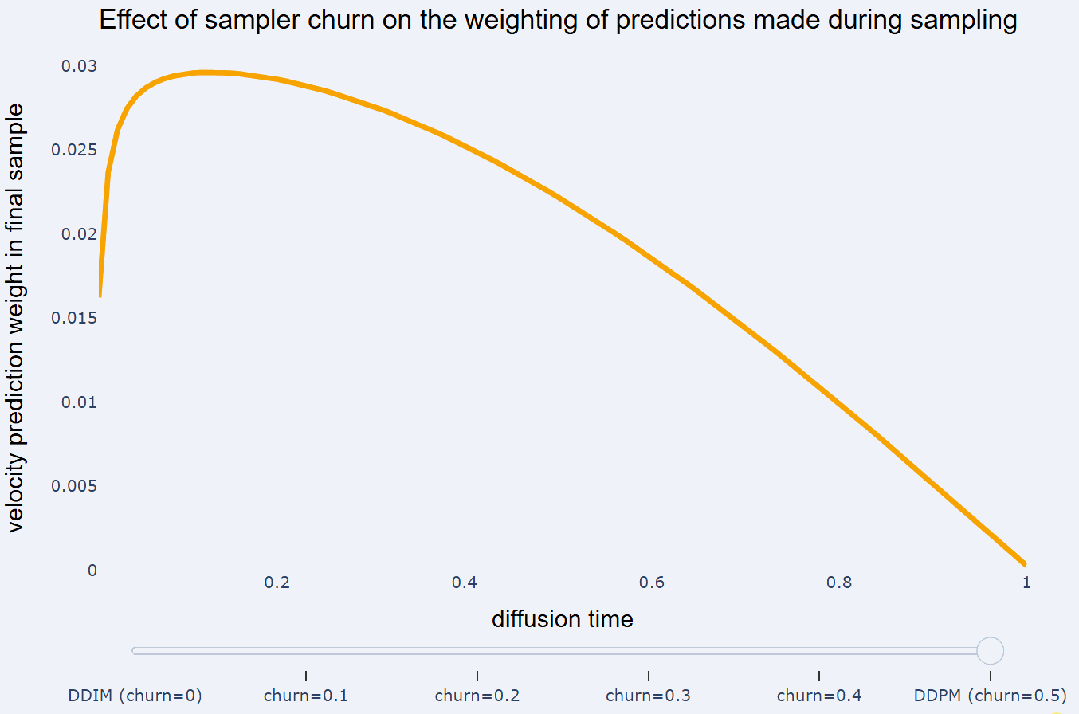
在这里,我们使用余弦噪声调度以及
预测将不同采样器都运行了 100 个采样步骤。忽略非线性相互作用,采样器产生的最终样本可以写成采样过程中做出的预测和高斯噪声 e 的加权和:
这些预测的权重 h_t 显示在 y 轴上,而 x 轴上显示不同的扩散时间 t。DDIM 会在此设置下对
预测赋予相等的权重,而 DDPM 则更注重在采样结束时所做的预测。另请参阅《Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models》以了解
中这些权重的解析表达式。
SDE 和 ODE 视角
前面,我们已经观察到扩散模型和流匹配算法之间的等价性。下面将使用 ODE 和 SDE 来形式化地描述正向过程和采样的等价性,以实现理论上的完整性。
扩散模型
扩散模型的前向过程涉及到随时间推移逐渐破坏一个数据,而该过程可使用以下随机微分方程(SDE)来描述:
其中 dz 是无穷小的高斯(即布朗运动)。f_t 和 g_t 决定了噪声调度。其生成过程由前向过程的逆过程给出,其公式为:
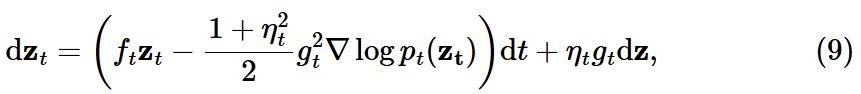
其中 ∇log p_t 是前向过程的分数。
请注意,这里引入了一个附加参数 η_t,它控制的是推理时的随机性。这与之前介绍的搅动(churn)参数有关。当离散化后向过程时,如果 η_t=0,则是恢复 DDIM;如果 η_t=1,则是恢复 DDPM。
流匹配
流匹配中 x 和 ε 之间的插值可以用以下常微分方程(ODE)描述:
假设该插值为
其生成过程只是在时间上反转这个 ODE,并将 u_t 替换为其对 z_t 的条件期望。这是随机插值(stochastic interpolants)的一个特例 —— 在这种情况下,它可以泛化成 SDE:
其中 ε_t 控制着推理时的随机性。
两个框架的等价性
这两个框架都分别由三个超参数定义:扩散的三个参数是 f_t、g_t、η_t,而流匹配的三个参数是 α_t、σ_t、ε_t。通过从一组超参数推导得到另一组超参数,可以显示这两组超参数的等价性。从扩散到流匹配:
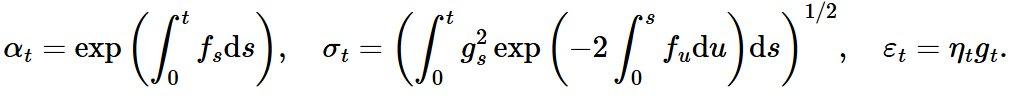
从流匹配到扩散:
总之,除了训练考虑和采样器选择之外,扩散和高斯流匹配没有根本区别。
结语
读到这里,想必你已经理解了扩散模型和高斯流匹配的等价性。不过,文中重点介绍的是流匹配为该领域带来的两个新模型规范:
网络输出:流匹配提出了一种网络输出的向量场参数化方案,并且其不同于扩散文献中使用的方案。当使用高阶采样器时,网络输出可能会有所不同。它也可能影响训练动态。
采样噪声调度:流匹配利用了简单的采样噪声调度 α_t = 1-t 和 σ_t = t,并且更新规则与 DDIM 相同。
该团队最后表示:「如果能通过实证方式研究这两个模型规范在不同的真实应用中的重要性,那一定会很有趣。我们将此留给了未来的工作。」
参考文献
Flow matching for generative modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M. and Le, M., 2022. arXiv preprint arXiv:2210.02747.
Flow straight and fast: Learning to generate and transfer data with rectified flow
Liu, X., Gong, C. and Liu, Q., 2022. arXiv preprint arXiv:2209.03003.
Building normalizing flows with stochastic interpolants
Albergo, M.S. and Vanden-Eijnden, E., 2022. arXiv preprint arXiv:2209.15571.
Stochastic interpolants: A unifying framework for flows and diffusions
Albergo, M.S., Boffi, N.M. and Vanden-Eijnden, E., 2023. arXiv preprint arXiv:2303.08797.
Denoising diffusion implicit models
Song, J., Meng, C. and Ermon, S., 2020. arXiv preprint arXiv:2010.02502.
Score-based generative modeling through stochastic differential equations
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S. and Poole, B., 2020. arXiv preprint arXiv:2011.13456.
Understanding diffusion objectives as the elbo with simple data augmentation
Kingma, D. and Gao, R., 2024. Advances in Neural Information Processing Systems, Vol 36.
Diffusion is spectral autoregression [HTML]
Dieleman, S., 2024.
Scaling rectified flow transformers for high-resolution image synthesis
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Muller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F. and others,, 2024. Forty-first International Conference on Machine Learning.
Elucidating the design space of diffusion-based generative models
Karras, T., Aittala, M., Aila, T. and Laine, S., 2022. Advances in neural information processing systems, Vol 35, pp. 26565—26577.
Knowledge distillation in iterative generative models for improved sampling speed [PDF]
Luhman, E. and Luhman, T., 2021. arXiv preprint arXiv:2101.02388.
Denoising diffusion probabilistic models
Ho, J., Jain, A. and Abbeel, P., 2020. Advances in neural information processing systems, Vol 33, pp. 6840—6851.
Progressive Distillation for Fast Sampling of Diffusion Models
Salimans, T. and Ho, J., 2022. International Conference on Learning Representations.
Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models
Lu, C., Zhou, Y., Bao, F., Chen, J., Li, C. and Zhu, J., 2022. arXiv preprint arXiv:2211.01095.
